

How to be a Successful ML PM

Written by Adrienne and Alexis
Today’s memo is sponsored by our friends at Faves: What trends are product giants focusing on? What articles and tweets do they consume? On Faves, you can find just that: Heads of Product at Facebook, Tiktok, Robinhood, and more curate the content that informs their thinking. Sign up today.
Over the past few years, Machine Learning (ML) became a ubiquitous term in tech companies, where now it’s hard to find companies not using any ML. With it, PMs who previously have no experience with ML are touching or becoming responsible for products that engage ML. When we first started managing a ML product, it was challenging to figure out where to come in and drive value — there were so many things to focus on from creating a natural user experience to technical aspects like increasing the speed of the model.
Here we share some traps we avoided and things we learned along the way to successfully managing an ML product.
Trap #1: Jumping into tasks without first diagnosing what type of ML PM work you’re thrust into
There are many flavors of PMs working on ML products. On one end of the spectrum, you might have a PM working at Cruise on fundamental ML research problems to make self-driving cars. On the other side of the spectrum, you have PMs that are focused on driving business value. In between, you might have a PM focused on optimizing a computationally intense model.
To make this memo useful, we narrowed the scope and focused on PMs on the right side of the spectrum. That is also where we have personal experience. If you’re working on the left side of the spectrum, your mileage will vary.

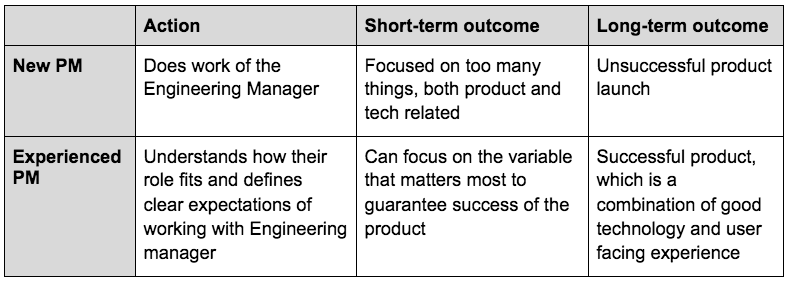
Trap #2: Doing the work of your Engineering Manager
An Engineering Manager will often be deeply focused on the technical aspects related to improving an ML model, such as how to increase the precision and recall. In general, it’s helpful to define expectations on roles of a PM vs. Engineering Manager up front, especially if you’re in a company with more overlap in those roles. The Engineering Manager’s role leaves another set of challenges well-suited for the PM:
How should ML inform and impact the user-facing experience?
For example, when Alexis was working on ML algorithms for Facebook News Feed, one of her projects was detecting and reducing bullying on News Feed comments. A different team had already built a general mature and high-quality model for detecting bullying, and she was tasked with applying it in comments. She recognized she could have the most impact on the product not by focusing on improving model quality, but rather by deciding what should happen to the user facing experience when the ML model determines a comment to be in the “gray area” of bullying:
Should the comment be hidden from users?
Should users be given an option to see the comments if they wanted to?
Should the comment be ranked at the bottom, so it’s visible but only after all the other comments have been seen?
What is the threshold of a “bullying” score that should trigger these different user facing treatments?
A good PM understands the user-facing ramifications of applying ML to a user facing experience.
Trap #3: Doing the work of your Operations Manager
Typically in a product team touching ML, it’s common to see a role that oversees the manual coordination and labeling required to transform raw data into data that computers can use for generating ML models. This role has many names, most commonly, an Operations Manager.
It can be tempting for a PM to get stuck in a hole of making sure the raw data is properly formatted for the model. After all, formatting data is a huge timesuck for any ML product. Ensuring this is usually the job of your Operations Manager -- you’ll be successful not by doing their job for them, but by giving them scaffolding to do their job well.
If it’s an Operations Manager1 role to transform the data, then a PM needs to do everything to ensure they can do their job well. One part is working with them to create programs that generate or collect enough raw data in the first place (quantity of data). Another part is giving guidance to the Operations Manager on what the transformed data should look like, so that the Operations Manager can create appropriate guidelines for labelers and data processors (quality of data).

Quantity of data
Quantity of data first starts with the PM estimating how much data is needed, for an ML model to reach a certain level of performance. This is a combination of user needs (i.e. in order for this product to be useful it needs to be accurate 99% of the time vs. 90%) and engineering needs (i.e. in order to achieve 99% accuracy, we need 200K data points on a monthly basis).
After the PM decides on the quantity of data needed, the PM must ensure there is enough data. Ask:
How am I going to source enough data?
Will it come from within the product or outside the product?
How can I build new product features that will increase the amount of data?
For example, one way Facebook increased the amount of data to identify spam was by building a “Report” feature. Now, Facebook posts have a “Report” button which allows users to report spammy content. This feature enables the team to collect more samples that users believe are problematic, which can then be labeled and used as an input for training data.

Quality of data
You can spend a lot of time focusing on data quantity, however, but if your data is not properly labeled and high quality, it won’t be useful for improving your ML model. One factor that determines quality of data, is label agreement rate. For example, Alexis worked with the Operations Manager to determine the required standard for agreement rates2, and also help clear the way to help them get there (e.g. resources for hiring additional or more experienced labelers).
And that’s it
As a PM there can be a lot of different things to focus on. In addition to laying out all the variables and identifying the ones that are both (1) most uncertain and (2) impact your product the most, you also have to consider the scope you’re in, and how it compares to the roles of your partner leads.
Operations Managers in ML teams oversee a team of labelers, create and improve upon labeling guidelines, increase agreement rates, and coordinate with PMs and Engineering Managers to produce a data output that is directly beneficial to creating or improving a model. Operations Managers sometimes also take on data cleaning efforts, to the extent it requires human eyes or non-programmatic coordination.
Agreement rate is how often multiple labelers labeling the same item come to the same conclusion. Getting a high agreement rate is critical for data quality, and to get there you need good labeling guidelines and well-trained labelers.